머신러닝을 이용한 주식 예측(2)
Pytorch를 이용해서 간단하게 구현해봤다.
Layer는 1개 LSTM으로 구현했으며
input의 종류는 다음과 같다.
- 시가, 종가, 불리저밴드, 5평선, 20평선, 거래량, OBV, MACD, STOCH
다 넣어봤다.
import torch.nn as nn
class LSTMStock(nn.Module):
def __init__(self):
super(LSTMStock, self).__init__()
self.fileName = None
self.trainRate = 0.9
self.inputSize = 12
self.outputSize = 1
self.layerNum = 1
self.hiddenDim = 128
self.epochCnt = 100
self.windowSize = 20
self.minmaxScaler = MinMaxScaler
self.minmaxList = ['Open','Close','BUPPER','BMIDDLE','BLOWER','SMA20','SMA5']
self.robustList = ['Volume','OBV']
self.originList = ['MACD','STOCHK','STOCHD']
self.lstm = nn.LSTM(self.inputSize, self.hiddenDim, self.layerNum, batch_first=True)
self.hiddenLayer = nn.Linear(self.hiddenDim, self.outputSize)
class선언시 nn.Module을 상속해준다.
input별로 특성에 따라 scaler를 다르게 적용시켰다.
def sliceWindow(self, stock_data):
data_raw = stock_data
data = []
for index in range(len(data_raw)-self.windowSize):
data.append(data_raw[index: index+self.windowSize])
data = np.array(data)
return data
def dataProcessing(self, data):
new_data = pd.DataFrame()
new_data['Date'] = data['Date']
for idx, scalerData in enumerate(self.scalerDataList):
for col in scalerData:
reshape_data = data[col].values.reshape(-1,1)
new_data[col] = self.scalerList[idx].fit_transform(reshape_data)
for col in self.originList:
new_data[col] = data[col]
if 'Date' in data.columns:
new_data = new_data.drop('Date',axis=1)
new_data.index = data['Date']
slice_data_x = self.sliceWindow(new_data)
slice_data_y = self.sliceWindow(new_data[self.output])
x_slice_data = np.array(slice_data_x)
y_slice_data = np.array(slice_data_y)
return x_slice_data, y_slice_data
LSTM의 경우 몇개의 시계열 데이터를 하나의 의미있는 데이터로 정할지 나누어 Input으로 넣어준다.
이를 위해 data를 잘라주어야 한다.
def forward(self, x):
h0 = torch.zeros(self.layerNum, x.size(0), self.hiddenDim).to(self.device).requires_grad_()
c0 = torch.zeros(self.layerNum, x.size(0), self.hiddenDim).to(self.device).requires_grad_()
out, (hn,cn) = self.lstm(x, (h0.detach(), c0.detach()))
out = self.hiddenLayer(out[:, -1, :])
return out
pytorch의 경우 model을 학습(호출)할때 forward함수가 실행된다. 즉 class안에서 forward를 선언하고 만들어 주어야 한다. LSTM의 경우 연산을 할 때 두개의 인자 필요
def run(self, model):
mm_scaler = MinMaxScaler(feature_range=(-1, 1))
std_scaler = StandardScaler()
#x_std = std_scaler.transform(self.inputX)
x_std = self.inputX
y_mm = mm_scaler.fit_transform(self.outY.values.reshape(-1,1))
x_slice = self.sliceWindow(x_std)
y_slice = y_mm[:-self.windowSize]
print(x_slice.shape)
print(y_slice.shape)
total_size = len(x_slice)
x_train = x_slice[:int(total_size*self.trainRate)]
x_test = x_slice[int(total_size*self.trainRate):]
y_train = y_slice[:int(total_size*self.trainRate)]
y_test = y_slice[int(total_size*self.trainRate):]
print('training size is {}'.format(x_train.shape))
print('test size is {}'.format(x_test.shape))
x_train = torch.from_numpy(x_train).type(torch.Tensor)
x_test = torch.from_numpy(x_test).type(torch.Tensor)
y_train_lstm = torch.from_numpy(y_train).type(torch.Tensor)
y_test_lstm = torch.from_numpy(y_test).type(torch.Tensor)
loss_function = nn.MSELoss(reduction='mean')
optimiser = torch.optim.Adam(model.parameters(), lr=0.01)
hist = np.zeros(self.epochCnt)
print(model)
start_time = time.time()
for t in range(self.epochCnt):
y_train_pred = model(x_train)
print(y_train_pred.shape)
print(y_train_lstm.shape)
loss = loss_function(y_train_pred, y_train_lstm)
print('Epoch ', t, 'MSE: ', loss.item())
hist[t] = loss.item()
optimiser.zero_grad()
loss.backward()
optimiser.step()
train_time = time.time() - start_time
print('Training Time : {}'.format(train_time))
plt.plot(hist, label='Training loss')
plt.legend()
plt.show()
loss function을 통해 차이를 확인하고 지속적으로 학습시켜준다.
총 데이터중 90%를 학습하는데 사용하고, 나머지 10%를 predict하는데 사용한다.
10%데이터로 예측결과
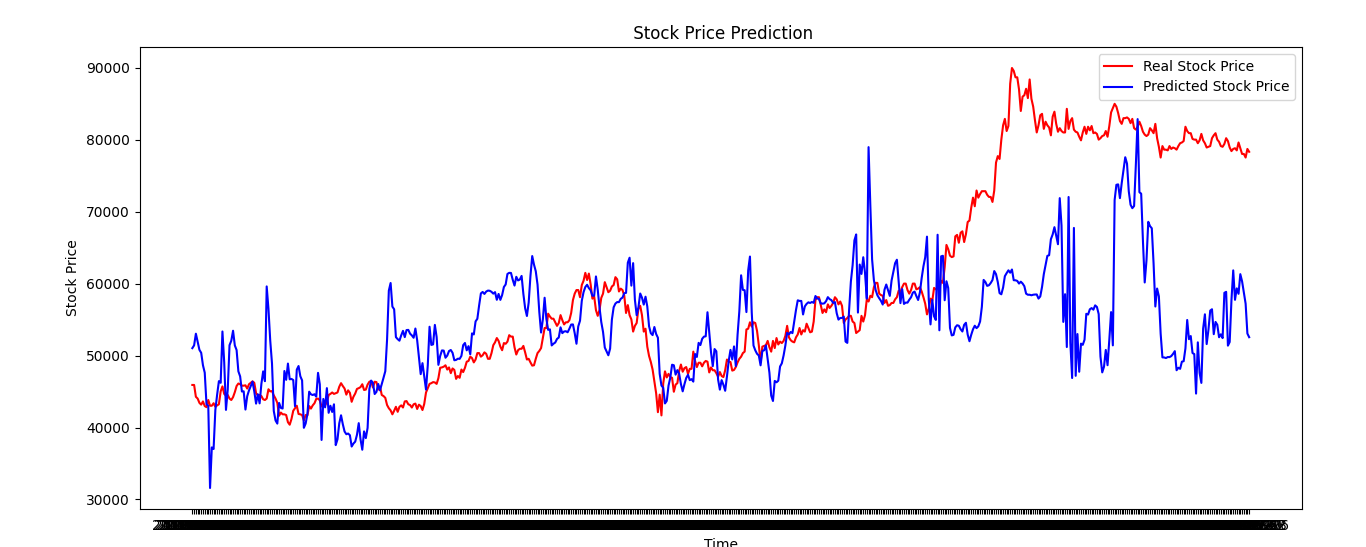
아주 엉망으로 나왔다..
너무나 많은 input이 문제인것 같아서, 이 중에 scaler를 적용하지 않는 input들을 빼고 다시 테스트 해봤다.
self.minmaxList = ['Open','Close','BUPPER','BMIDDLE','BLOWER','SMA20','SMA5']
self.robustList = ['Volume','OBV']
self.originList = []
테스트 결과
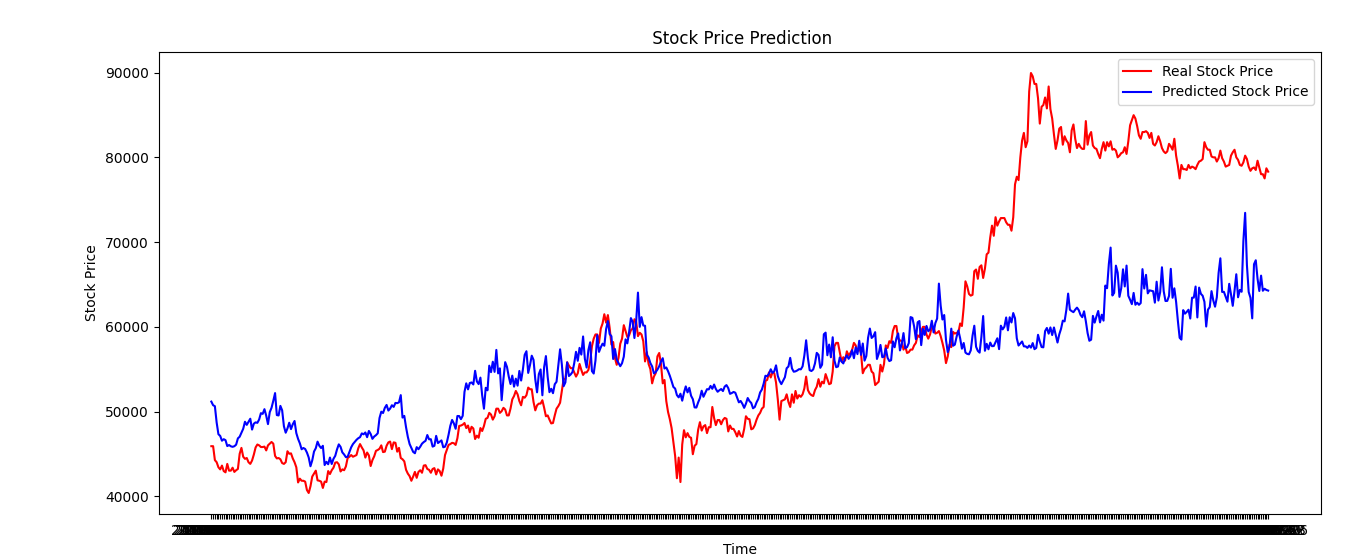
초반에는 파형은 비슷해보이나, 급격한 가격의 변화의 경우 따라가지 못하는걸 알 수 있다.
문제점
- predicted data가 실제 realdata보다 하루 늦은날짜에 비슷한 data를 출력한다.
- 가격이 급격하게 상승하는 경우 이를 따라가지 못한다.
1번의 경우에는 아마 최대한 오차범위를 줄이려고 하다 보니까 전 가격을 따라갈경우 범위가 줄어들다보니 된것 같다.
2번의 이유는 잘 모르겠다.. 전 종가의 가중치가 제일 높을 경우 이를 따라갈거라고 생각했는데..
가격을 맞춘다기 보다는 상승 하락을 맞추는 것으로 변경할 예정