머신러닝을 이용한 주식 예측(5) (강화학습)
다양한 방식을 직접해보고 싶어서 이번에는 Reinforcement, 즉 강화학습을 이용해보고 싶었다.
이론
강화학습이 기존의 다루었던 LSTM과 다른점은, 스스로 최상의 보상을 찾는 다는 것이다.
예를들어 LSTM에서는 Close(종가)값을 맞추기 위해 학습한다면,
강화학습의 경우에는 수 많은 행동(주식에서는 매수,매매,홀딩)을 통해서 나의 자산이 최대가 되도록 학습하는 방법이다.
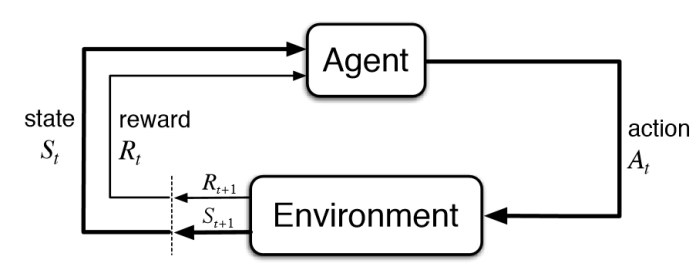
사진을 보면 machine은 특정 행동을 한 다음, 이에 대한 보상, State 두개를 알게 된다.
즉 Machine은 state를 고려하여 보상이 최대가 될 수 있도록 학습한다.
코드
file: DQN.py
강화학습을 편리하게 사용할 수 있는 python 모듈인 stable_baselines3를 이용하여 구현하였다.
environment를 구현하면 이를 model에 선언하여 사용할 수 있다.
이 때 environment를 구현을 위해 필요한 함수는 아래와 같다.
class StockTradingEnv(gym.Env):
def __init__(self):
self.action_space # step시 action에 따라 행동을 결정
self.observation_space #state
def __reset__(self): #한번의 학습이 끝나고 reset함수가 실행된다.
def __step__(self, action): # Machine이 행동할 때 실행되는 함수다.
def __render__(self): #한번의 학습이 끝나고 난후 reset되기전 render를 통해 결과확인
def __close__(self): #마지막 close될때 실행되는 함수
step 함수
총 3개의 행동으로 구분하였다.
Buy, Sell, Holding
open_price = self.stock_data.loc[self.time_stamp, 'Open']
close_price = self.stock_data.loc[self.time_stamp, 'Close']
action_type = action[0]
amount = action[1]
# 주식을 사는 행위
if action_type < 1:
possible_amount = int(self.balance / open_price)
prev_cost = self.stock_amount * self.avg_price
# 가능한 양에서 일정만큼만 산다.
buying_amount = int(possible_amount * amount)
buying_cost = buying_amount * open_price
self.balance -= buying_cost
if self.stock_amount + buying_amount >0:
self.avg_price = (prev_cost + buying_cost) / (self.stock_amount + buying_amount)
else:
self.avg_price = 0
self.stock_amount += buying_amount
action_type의 경우 float단위로 나오도록 설정하였다. 기본적으로 reinforcement에서는 float가 int에 비에 더 정확(?)할것 같아서.
사는 경우 무조건 한번에 다 사는것이 아닌 현재 살 수 있는 금액 중 얼마만큼을 machine이 선택할 수 있도록 하였다.
elif action_type < 2:
selling_amount = int(self.stock_amount * amount)
self.stock_amount -= selling_amount
self.balance += selling_amount * open_price
파는 경우도 마찬가지다.
Simulation 결과
삼성전자의 모든날짜를 기준으로 학습
결과값
시작금액은 10,000,000(천만원)
2000번의 학습후
63085440.0
61143280.00000001
58831733.95804194
아주 높은 수익률을 보였다. 그 이유는 같은 주식으로 수행하도록 했기 때문
추후 다른 주식데이터도 학습하고 다른 주식으로 수행할 수 있도록 코드 수정 필요